Importing articles
Architecture overview
XalokNext:6 comes with WfImporterBundle. This bundle offers some services that should ease importing items, be it articles or images or users or any other entity defined in XalokNext or the project.
Usually, at least in the case of migrating the news archive to XalokNext, the work is done through a command, but WfImporterBundle's services can also be used to import data from a controller.
The role of the importing command is to configure the options required by the project and do some minimal work of wiring the services depending on the source type used. Then, the command is delegating work to the CliImportManager.
Since most (if not all) projects until now required importing news dumped in XML files, WfImporterBundle comes with wf:cms:importer:xml command that configures some options common to all projects and wires the importers to use XML extractors.
The options configured by the command are made available as wf_importer.options (alias: Wf\Bundle\ImporterBundle\Options\ImporterOptions) service, that extends Symfony's ParameterBag. Read more here
CliImportManager invokes a source locator - a service in charge of saying which is the next item (article/image/user/etc.) to be imported.
Then, this data is passed to the importer of the given item type (ArticleImporter, ImageImporter, etc.);
The importer optionally passes this data to a context extractor, a service that converts the data from the original format to an array that XalokNext can work with. In the case of importing XML files, WfImporterBundle has an article content extractor that converts the data read from the XML file to the array. (The wf:cms:importer:xml command deals with injecting this extractor in the ArticleImporter). The content extractor should also be used if the original data is an array (e.g.: it comes from a DB) but the column names used in this original DB are different from the ones that XalokNext uses.
Then, the importer passes this data to a mapper service, which is in charge of converting the plain data to a format expected by XalokNext. For example: most likely the source will contain the categories/tags slugs (or titles) as string. It's the mapper that is in charge of converting this data to Category/Tag entities that XalokNext expects.
The mapper is also in charge of importing images/videos/etc. from their original URLs and turning them into Image/Video/etc. entities.
In the case of import commands, the importer's importSource($source): ImportableEntityInterface) is invoked. This method only calls the extractor (if it's been set for this importer by the command) and then passes the array to the importData($data): ImportableEntityInterface method - this can be used if importing data from controllers is needed.
In the project , the ArticleImporter has to be extended from the base. In case of make a previous extraction to the data, this has to be done before the importData($data) method call.
use Wf\Bundle\ImporterBundle\Importer\ArticleImporter as BaseImporter;
class ArticleImporter extends BaseImporter
{
public function importSource($source): ImportableEntityInterface
{
if ($this->extractor !== null) {
$data = $this->extractor->extract($source);
}
return $this->importData($data);
}
}In addition , the importData method could be extended in order to add the necessary extra code.
After the item importer's work has been done, the CliImportManager calls the source locator's markImport($source) (in case of success) or markError($source, \Throwable $exception) (in case of failure) to mark the item as being imported. For example: in the case of the XmlFileSourceLocator, it can move the files to either a processed or an error directory, so that a second invocation of the command doesn't import the same items over & over (to avoid crashes due to memory leaks, the importer command should have an iterations options, when this option is set, the CliImportManager exits after importing iterations items, so the command is usually invoked many times in a loop). In the case of working with a DB source, the source locator's markImport command could update a column in the original DB to indicate that the item was imported and then use this column's value in the locate method to skip these items.
Commands
WfImporterBundle comes with wf:cms:importer:xml command, but the code of this command is very slim, it only does some wiring related to importing XML sources and defers the bulk of the work to the CliImportManager. You're welcome to add a custom command rather than attempt to customize the default one if more options are needed. When the importer command is created in the project, the cliImportManager has to be extended from the base
use Wf\Bundle\ImporterBundle\CliImportManager;
class ImportCommand extends Command {
protected function execute(InputInterface $input, OutputInterface $output)
{
$this->importManager->import($input, $output);
}
}The configuration options like: source_path, iterations_number, error_path and other ones in the importerCommand are set in the configure() method.
use Wf\Bundle\ImporterBundle\Options\ImporterOptions;
class ImportCommand extends Command
{
protected function configure()
{
$this
->addOption($name, $shortcut = null, $mode = null, $description = '', $default = null)
;
}
}SetLoggerTrait
Most of the services are injecting the monolog.logger.import service in their constructor. However, most (if not all) of these services have a setLogger method:
public function setLogger(Psr\Log\LoggerInterface\LoggerInterface $logger): self;The setLogger method is required because in the case of importer commands, the monolog.logger.import logger is swapped with a logger that outputs to the console for convenience during development. During running the migration on PRO, the output of the command can be piped to a file (> /var/log/xalok/migration.log).
For this reason WfImporterBundle comes with a SetLoggerTrait, it defines a $logger property and a setLogger method. To use it:
class Service {
use \Wf\Bundle\ImporterBundle\Traits\SetLoggerTrait;
}ImporterOptions
The options configured by the importing command are available through the wf_importer.options (alias: Wf\Bundle\ImporterBundle\Options\ImporterOptions) service, that extends Symfony's ParameterBag. To make working with options easier and less bug-prone, add getters (and "has-ers", if necessary) to the ImportOptions class of this service for each of the options. For example, if a command configures the iterations options, inject the wf_importer.options service (if it's not already injected, most importer related services in XalokNext already have them injected) and access: $this->options->getIterations().
When overwritting the ImporterOptions in the project, overwrite the property in the services coming from XalokNext too and annotate it with the project's class to enable autocompletion, for example:
class ImageMapper extends \Wf\Bundle\ImporterBundle\Mapper\ImageMapper
{
// ...
/** @var \App\Bundle\CmsAdminBundle\Migration\ImporterOptions */
protected \Wf\Bundle\ImporterBundle\Options\ImporterOptions $options;
// ...
}Source locators
Traditionally the data was imported from XML documents, but WfImporterBundle doesn't depend on this workflow. One can implement a custom source locator to import data from other source types, for example a database server containing the source data.
Creating a custom source locator
A custom source locator must implement SourceLocatorInterface. There are three methods of interest in this interface:
public function locate(): \Generator;This method should search for the next source to be imported and yield it:
yield $type => $source;$type is the type of entity that should be imported (article/image/user/etc.) - CliImportManager needs this to know to which importer (ArticleImporter/ImageImporter/etc.) it should pass the source. This is the reason why the XmlFileSourceLocator instantiates a Symfony Crawler with the contents of the file (instead of deferring this to the importer): sometimes the type of the source is contained somewhere inside the XML file.
$source can be anything - it'll be handled by the methods and services described later.
In the case of XmlFileSourceLocator, its locate method searches the directory specified through its source-path command option for XML files. The $source in this case is a XmlFileSource object that wraps information about the found file and also a Symfony Crawler instance initialized with the contents of the file.
public function markImport($source);This method receives the $source yielded by the locate method. It's called when the importing of this source has been successful, to mark this somehow so that later invocations of the import command skip this news. In the case of XmlFileSourceLocator it moves the source file to the directory specified through the processed-path command option - if it exists. Leave out this option when invoking the command to leave the XML files in the source-path directory - useful while developing where multiple iterations are probably required.
public function markError($source, \Throwable $exception);Same as the markImport method, but called when there's an error importing the news. In the case of XmlFileSourceLocator it moves the source file to the directory specified through the error-path command option - if it exists. Leave out this option when invoking the command to leave the XML files in the source-path directory - useful while developing where multiple iterations are probably required.
To use this custom source locator, either write a compiler pass that changes wf_importer.manager's first argument to your service, or inject it in a custom importer command and then in its execute method:
protected function execute(InputInterface $input, OutputInterface $output)
{
$this->importManager->setSourceLocator($this->sourceLocator);
// (optionally) other setup, like setting extractors
$this->importManager->import($input, $output);
}Extractors
In case the source locator yields a $source that is not an array - as it is the case of the XmlFileSourceLocator, this optional extra service transforms the $source to an array - using the XmlFileSource->getCrawler() instance to read data from the XML.
It can also be useful in other cases - for example, when reading the sources from a database, even though the source locator yields an array, if the column names are different from the ones used by XalokNext (or a language different than English is used), the content extractor can do the "translation":
$data['category'] = $data['categoria'];
unset($data['categoria']);If one needs to write a custom extractor, write the service, write a new command where both this service and the item's importer are injected, and call the importer's setExtractor method in the execute method of the command, before invoking the CliImportManager.
Returned array keys
All the properties of the array returned by the extractor must have a corresponding property or setter in the imported property. That is, if the extractor (or mapper) puts a key xY in the returned array, there must be either an $xY property or a setXY method in the imported entity.
There are some special fields required by Xalok that must be set:
sourceandsourceId: these are needed for all imported entities. They're used to be able to figure out when an entity has been imported and what XalokNext entity must be updated if the same source is found again.category: all articles must belong to a categorytemplate: all articles must have a templatepublishedAt: add this field in theArticleExtractor, the article will be marked as published (most likely all migrated articles must be published by default)
Mappers
The data that comes from the source locator's locate method, optionally passed through the content extractor's extract method (if a content extractor is defined for that data type) is then passed to a mapper service.
The main task of a mapper is to convert the plain data coming from the source to the corresponding format used by XalokNext.
For example: the incoming data will likely have a string value for $data['category'] (either the slug or the title) - the mapper would be in charge of finding the corresponding categories in XalokNext. Same goes for tags & users.
It's also likely that the incoming data has a string value for embedded resources (images/videos/etc.). For this, the AbstractMapper (that should be extended by all mappers) injects the wf_importer.importers_collection service, use this service's ->get('image') method to get the image importer and convert the string to an Image entity.
To favor code reusability, there's a MapperUtil (wf_importer.mapper_util) service that should do the heavy lifting of the mapping - that's because, for example, converting tags from strings to Tag entities might be needed in both ArticleMapper and in ImageMapper. Similarly, mapping the category field might be needed for both articles and videos.
Adding a new mapper
A new mapper must implement MapperInterface. To register it as a mapper, add to its service definition this tag:
<tag name="wf_importer.mapper" type="__ITEM_TYPE__" />Module builders
One of the most demanding tasks when mapping fields for articles is building the modules array - the data used by the editor to render the body of an article.
Every $data array that comes to the ArticleMapper must have a template key, specifying the template used to render that article. For each template used when importing, a service must be created (likely extending AbstractModulesBuilder) and tagged with
<tag name="wf_importer.modules_builder" template="article-__TEMPLATE_NAME__" />Have a look at AbstractModulesBuilder::addTitleModule method for how the modules builder is used.
Note that the template attribute of this tag is prefixed with article-, this is to avoid confusion in case boards or other Page types must be imported.
Extractors vs Mappers
The work of getting the source data into a data understood by XalokNext has been divided in these two types of services.
Since both services work with arrays of data, it can be confusing as to what service to use to do the corresponding work. As a general rule of thumb: if the processing involves accessing external resources (access to the DB, or access to the network), do this processing in the mapper, for all other cases, do the processing in the extractor.
Because it's common that there are many particular cases in the imported data, these particular cases should be handled in the extractor services. The extractors work with PHP data types, making the extractor's code more easily testable, whereas the mapper (typically) needs access to a database, to transform from the PHP data type to a "XalokNext data type".
Examples:
- related entities: an extractor returns the (
string) slug of a category or tag, or the (string) username of an author, the mapper converts this string to aCategory/Tag/WfUserentities - related assets: an extractor returns the (
string) URL, the mapper invokes theImageImporterand returns the relatedImageentity - modules: an extractor return the (flat
array) data required to build modules, the mapper builds (using a module builder) themodulesto be stored in the XalokNext DB, using the roles and nesting of the modules as defined in the articles' twigs. - mapping old categories to XalokNext categories: many times in the importing process categories from the old CMS are "deleted", the news that belonged to these categories will be imported to new categories. Usually this involves some scalar maps, move all news corresponding to category
xto categoryy. Do this in the extractor. - mapping old authors to XalokNext users: same as for categories, if it doesn't involve access to the DB, do it in the extractor.
Gotchas
Article versions deleted
Upon reimporting an article, all of its versions are deleted from the DB. This is to ease the case of reimporting the article, it's difficult to know by default what the best course of action should be if an imported article is being reimported and there are multiple versions - should it reimport the first version (this is the version that was created initially)? Should it overwrite the last version, thus overwritting any changes made manually by the users? One should take special care to check if there are any articles in this situation that need to be reimported and take the appropriate decision for each case.
Overwriting an importer
The work done by the importer is mostly agnostic of the type of item being imported. If you feel the need to overwrite an importer, consider if there's an alternative in using an extractor or the importer's mapper for the job.
One example of unnecessary work done through overwriting the importer is found in some projects where, upon reimporting an existing article, the tags/authors of that article were deleted from the DB "manually", by running SQL queries. This can be easily avoided by setting the $data['tags'] to an empty array if the source doesn't have any tags.
Messenger bus disabled
The messenger bus (used to queue jobs for invalidating articles) is disabled from CliImportManager. This is because the CliImportManager is usually invoked before the site goes to PRO, so the imported articles wouldn't exist in Varnish. Disabling it thus should avoid adding many unnecessary clear cache jobs.
V7 features
The Xalok v7 implements the Amazon SQS feature for handle files importation which are stored in a S3 Bucket.
This implementation offers some advantages like time process optimization , most of all the time saved for transfer and manage the importation files. The main idea is that the client will add directly the files to an Amazon S3 Bucket , following a file structure provided by Xalok. This can be done following the Amazon Cli commands which execution takes just a few seconds (could take more depending on the amount of files) however this process is very efficient and reduces the complex of managing the files using other methods.
Installation and configuration
Dependencies installation
`composer require aws/aws-sdk-php`
`composer require enqueue/sqs`SQS configuration
First of all , you need to enable the sqsQueue in the app/admin/AdminKernel.php:
class AdminKernel extends PublicKernel
{
protected bool $enableSQSQueue = true;
}The sqs configuration file has to be created in src/App/Bundle/CmsAdminBundle/Resources/config/third_party/enqueue_bundle_sqs.yml
enqueue:
default:
transport:
dsn: "sqs:?key=%wf_importer_key%&secret=%wf_importer_secret%®ion=%wf_importer_region%"
client: ~
parameters:
wf_importer_queue_name: '%wf_importer.queue.name%'Gaufrette configuration
In order to manage the files stored in the Bucket S3, you have to use the Gaufrette Filesystem Adapter.
The Gaufrette configuration file has to be created in src/App/Bundle/CmsAdminBundle/Resources/config/third_party/migration_gaufrette.yml
knp_gaufrette:
adapters:
migration_resources:
local:
directory: "%kernel.root_dir%/../data/migration/originalFiles/resources"
create: true
filesystems:
migration_resources:
adapter: migration_resourcesBoth files: enqueue_bundle_sqs.yml and migration_gaufrette.yml needs to be added to the app/admin/config/config.yml file
imports:
- { resource: "@AppCmsAdminBundle/Resources/config/third_party/enqueue_bundle_sqs.yml" }
- { resource: "@AppCmsAdminBundle/Resources/config/third_party/migration_gaufrette.yml" }Amazon sqs configuration
All the parameters of the Amazon sqs are set in the local.yml project.
wf_importer_key: XXXXX
wf_importer_secret: XXXXX
wf_importer_region: XXXXX
wf_importer.queue.name: XXXXXTesting Amazon Queue.
For testing the sending and message reception , these CLI commands can be used:
Sending message to queue SQS:
aws sqs send-message --queue-url https://sqs.eu-west-1.amazonaws.com/574234807482/<bucketName> --message-body '{"test":"hello world"}'Message reception from queue SQS:
aws sqs receive-message --queue-url https://sqs.eu-west-1.amazonaws.com/574234807482/<bucketName>Migration Directory Structure
There is a directory structure to organize the files used for the migration.
For local environment these directories has to be created and being excluded from git:
- **app/data/migration/migration: where the xml files are stored for being processed.
- app/data/migration/originalFiles/xmls: where the original xml files are stored.
- app/data/migration/originalFiles/resources/ : where are stored the media resources related to articles stored in xmls directory. These need to have this structure: app/data/resources/fileId/resourceName.fileExtension
- app/data/migration/in_queue/: where the files added in the queue are stored for the future message consumption.
- app/data/migration/in_queue/done: were the file is moved after a successful migration process.
- app/data/migration/in_queue/error: were the file is moved when an error has occurred.
For dev and production environment, the Amazon S3 bucket must have this directory structure :
bucketName/originalFiles: where the xml files are stored for being processed.
bucketName/originalFiles: all the files needs to be placed here, ordered in two subdirectories:
bucketName/originalFiles/xmls: the xml files are stored here . The name of then has to be the Id related to the content to migrate.
bucketName/originalFiles/resources: all file resources as: photo, audio, video, image and more, needs to be placed here creating a directory with the same id of the xml content which is related. For example:
bucketName/migration/originalFiles/resources/fileId/resourceName.fileExtensionbucketName/in_queue: where the files added in the queue are stored for the future message consumption.
bucketName/in_queue/done: were the file is moved after a successful migration process.
bucketName/in_queue/error: were the file is moved when an error has occurred.
The previous files can be uploaded to the bucket S3 using two options :
Using AWS S3 CLI
https://docs.aws.amazon.com/cli/latest/reference/s3/#cli-aws-s3
Before use it , needs to be installed and configured.
Installation:
https://docs.aws.amazon.com/es_es/cli/latest/userguide/getting-started-install.html
AWS S3 CLI Configuration
aws configureThese data will be requested:
- AWS Access Key ID:
- AWS Secret Access Key:
- REGIÓN:
Using a user interface
For example : https://www.crossftp.com/
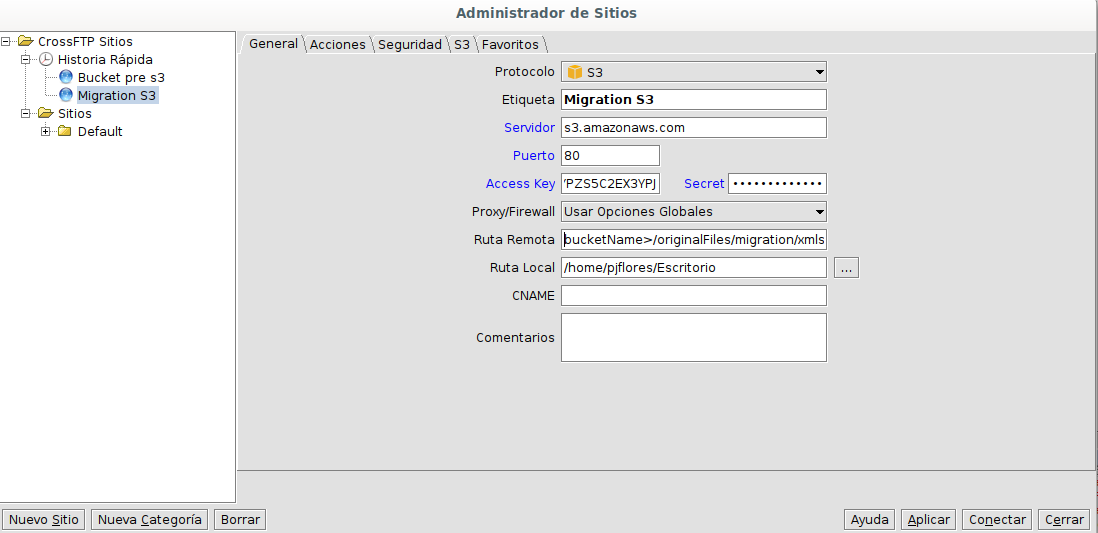
The config file for Amazon S3 is allocated in vich_uploader_queue_s3.yml.
For local environment, use the Amazon S3 credentials has to be added in the local.yml file.
s3_bucket_migration: xxxxIn addition , the vich_uploader_queue_s3.yml needs to be imported to the project config-dev.yml.
imports:
- { resource: "@WfCmsBaseBundle/Resources/config/third_party/vich_uploader_queue_s3.yml" }The "wf_importer.locator.xml_queue" service has to be extended and the getType($source) method needs to be implemented in the project. In case of content importation of 'article' type. In order to do this , you need to create the src/App/Bundle/CmsAdminBundle/ImporterBundle/SourceLocator/Queue/XmlQueueSourceLocator.php file:
class XmlQueueSourceLocator extends \Wf\Bundle\ImporterBundle\SourceLocator\Queue\XmlQueueSourceLocator
{
protected function getType($source): string
{
return 'article';
}
}In addition, add the compiler pass associated to XmlQueueSourceLocator: src/App/Bundle/CmsAdminBundle/DependencyInjection/CompilerPass/XmlQueueSourceLocatorCompilerPass.php:
use App\Bundle\CmsAdminBundle\ImporterBundle\SourceLocator\Queue\XmlQueueSourceLocator;
class XmlQueueSourceLocatorCompilerPass implements CompilerPassInterface
{
public function process(ContainerBuilder $container)
{
$container->getDefinition('wf_importer.locator.xml_queue')
->setClass(XmlQueueSourceLocator::class);
}
}Commands
wf:cms:migration:make-queue
This command is used to read all files contents on specific route and creates the sqs.
Command options
- MAX_FILES: Total number of files processed per run
- FILE FORMAT: XML by default
wf:cms:importer:xml-queue
Gets the files from the sqs using the XmlQueueSourceLocator and then , runs the import process managed by the CliImportManager.
use Wf\Bundle\ImporterBundle\SourceLocator\SourceLocatorInterface;
use Wf\Bundle\ImporterBundle\Importer\ImportersCollection;
use Wf\Bundle\ImporterBundle\Extractor\ArticleXmlExtractor;
class XmlQueueImporterCommand extends Command
{
protected function execute(InputInterface $input, OutputInterface $output)
{
$this->importersCollection->get('article')->setExtractor($this->articleExtractor);
$this->importManager->setSourceLocator($this->sourceLocator);
$this->importManager->import($input, $output);
}
}You could extend this command in the project if you want to add some extra config.
On this example , the source locator was already established when it was extended in the project and the getType() method was implemented .
Extractors
The data needs to be extracted from the source in order to convert it in array and then process it.
Article Extractor
You have to extend the ArticleXmlExtractor in order to add logic for data extraction. This is a simplified example using objects:
use App\Bundle\CmsAdminBundle\ImporterBundle\Objects\Article\Item;
use Gaufrette\Filesystem;
class ArticleXmlExtractor extends \Wf\Bundle\ImporterBundle\Extractor\ArticleXmlExtractor
{
public function extract($source): array
{
$source = $this->filesInQueue->read($source);
$content = mb_convert_encoding($source, 'UTF-8');
try {
$ItemObject = $this->serializer->deserialize($content, Item::class, 'xml');
$ItemObject = $this->toArray($ItemObject);
return $ItemObject;
} catch (\Exception $exception) {
//handle exception
}
}
public function setFilesInQueue(Filesystem $filesInQueue)
{
$this->filesInQueue = $filesInQueue;
}
}For this example, the Item object has to be created following the xml structure in order to extract the data and place it in an array. Feel free to extract the data using other methods , however, the final result has to be an array with the xml data.
ArticleExtractor CompilerPass
use App\Bundle\CmsAdminBundle\ImporterBundle\Extractor\ArticleXmlExtractor;
class ArticleXmlExtractorCompilerPass implements CompilerPassInterface
{
public function process(ContainerBuilder $container)
{
$container->getDefinition('wf_importer.xml.article-extractor')
->setClass(ArticleXmlExtractor::class)
->addMethodCall('setSerializer', [new Reference('serializer')])
->addMethodCall('setFilesInQueue', [new Reference('gaufrette.migration_in_queue_filesystem')])
;
}
}Mappers
The mappers associated the extracted data with entity fields before their creation.
ArticleMapper
Extend the vendor/wfcms/standard/Wf/Bundle/ImporterBundle/Mapper/ArticleMapper.php in the project in order to adapt the modules mapping.
src/App/Bundle/CmsAdminBundle/ImporterBundle/Mapper/ArticleMapper.php
ArticleMapper CompilerPass
Add the compiler pass src/App/Bundle/CmsAdminBundle/DependencyInjection/CompilerPass/ArticleMapperCompilerPass.php
use App\Bundle\CmsAdminBundle\ImporterBundle\Mapper\ArticleMapper;
public function process(ContainerBuilder $container)
{
$container->getDefinition('wf_importer.mapper.article')
->setClass(ArticleMapper::class)
->addMethodCall('setFileResources', [new Reference('gaufrette.migration_resources_filesystem')])
;
}setFileResources makes reference to the filesystem adapter configured with the resources in the base Xalok project.
Modules builder
The modules builder belongs to the mapper process, on this file the extracted data is associated to the object modules, creating the roles and module structure.
The Wf/Bundle/ImporterBundle/Mapper/ModuleBuilder/ArticleDefaultModulesBuilder.php has to be extended in the project for handle all the modules present in the import file
Modules builder CompilerPass
use App\Bundle\CmsAdminBundle\ImporterBundle\Mapper\ModuleBuilder\ArticleDefaultModulesBuilder;
use Symfony\Component\DependencyInjection\Compiler\CompilerPassInterface;
use Symfony\Component\DependencyInjection\ContainerBuilder;
use Symfony\Component\DependencyInjection\Reference;
class ArticleDefaultModulesBuilderCompilerPass implements CompilerPassInterface
{
public function process(ContainerBuilder $container)
{
$container->getDefinition('wf_importer.modules_builder.default')
->setClass(ArticleDefaultModulesBuilder::class)
->addMethodCall('setPropertyAccessor', [new Reference('fos_elastica.property_accessor')])
;
}
}Prepare a migration
- Upload the original xml files from local to the S3 bucket.
aws s3 cp <bucketName>/ s3://<bucketName>/original_files/xmls --recursive- Copy the xml files on the migration directory.
aws s3 cp s3://<bucketName>/original_files/xmls s3://<bucketName>/migration/ --recursive- Copy all resources in the resources' directory.
aws s3 cp s3://<bucketName>/original_files/resources s3://<bucketName>/resources/- Send messages to queue.
./app/admin/console wf:cms:migration:make-queue -m 10- Process queue messages (only local environment).
while true; do ./app/admin/console wf:cms:importer:xml-queue -i 1 ; doneIf the process was completed successfully , the entity should be created on db and the xml file moved to done directory. In case of error, the file should be moved to error directory.
Relevant S3 commands
- List migration bucket files.
aws s3 ls s3://<bucketName>- Delete all files from bucket migration.
aws s3 rm s3://<bucketName> --recursive- Copy xml files from local environment to migration bucket.
aws s3 cp <filesDir>/ s3://<bucketName>/original_files/xmls --recursive- Download files from bucket migration
aws s3 cp s3://<bucketName>/original_files/ . --recursive- Copy files from error directory to migration directory.
aws s3 mv s3://<bucketName>/in_queue/error s3://<bucketName>/migration/ --recursive- Total files correctly migrated.
aws s3 ls s3://<bucketName>/in_queue/done/ --recursive --summarize | grep "Total Objects:"- Total files correctly migrated with errors.
aws s3 ls s3://<bucketName>/in_queue/error/ --recursive --summarize | grep "Total Objects:"